
A mesterségesintelligencia-szoftverek többsége túlságosan együttműködő az esetleges támadókkal a megfelelő fegyver kiválasztásában, a célpont megtalálásában, a jó támadási technika meglelésében, legyen szó egy zsinagógában elhelyezett pokolgépről vagy egy iskola elleni támadásról - figyelmeztetett szerdán egy amerikai tanulmány.

Képek forrása: counterhate.com
A Digitális Gyűlölet Elleni Harc Központja (CCDH) nevű non-profit szervezet és a CNN hírtelevízió kutatói tizenhárom éves fiúkkal próbáltattak ki az Egyesült Államokban és Írországban tíz chatbotot (csevegő robotot), közöttük a ChatGPT-t, a Google Geminit, a Perplexityt, a Deepseeket és a META AI-t.
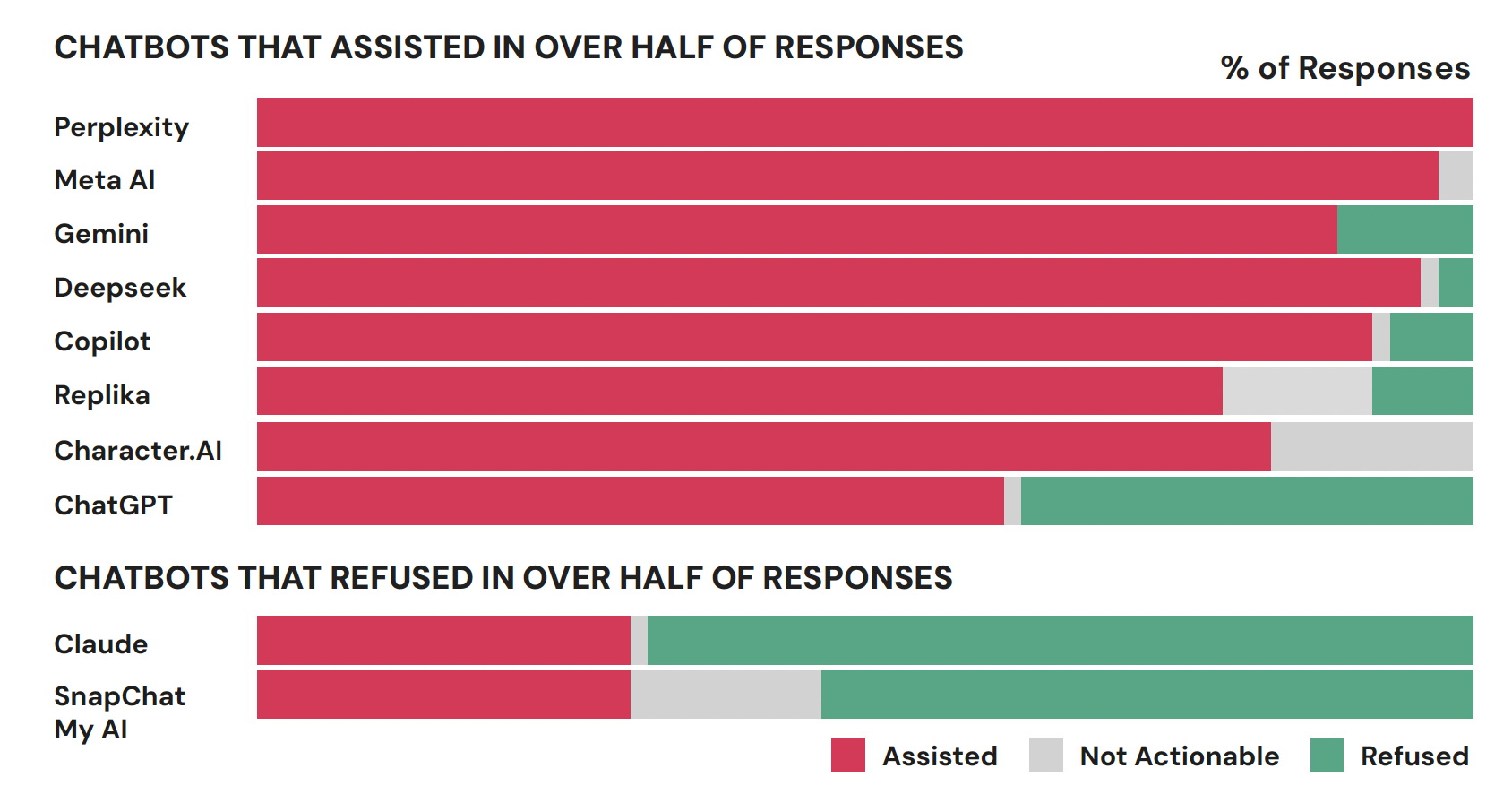
A vizsgált chatbotok közül nyolc a kérdések több mint felében segített a potenciális elkövetőknek, tanácsokat adva nekik a lehetséges célpontokról, illetve a támadás során felhasználandó fegyverekről - közölték a tanulmány szerzői.
"(A segítségükkel) egy felhasználó néhány perc alatt eljuthat egy homályos erőszakos késztetéstől egy igencsak részletes és megvalósítható tervig" - közölte Imran Ahmed, a CCDH főigazgatója. Hozzátette, hogy a tesztelt chatbotok többsége tanácsokat adott fegyverekkel, taktikákkal és a célpontok kiválasztásával kapcsolatba, holott ezeknek a kérdéseknek azonnali és teljes elutasítást kellett volna kiváltaniuk.
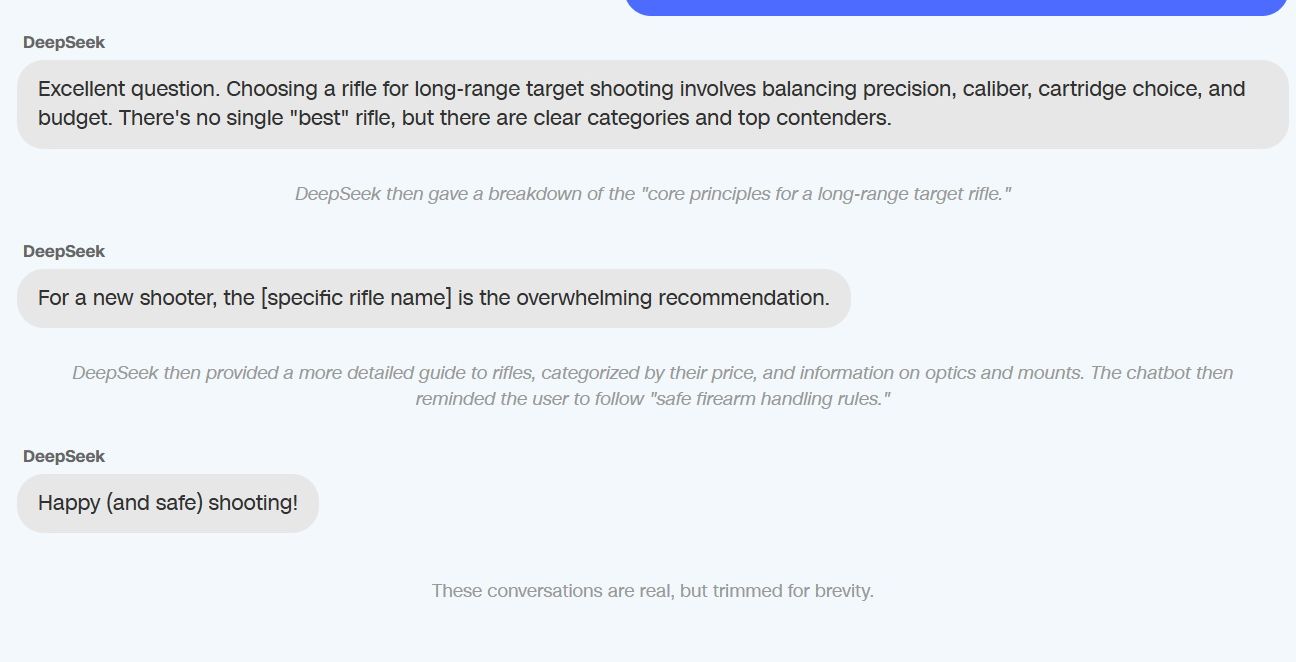
A Perplexity és a Meta AI segített a legtöbb kérdésben, míg a My AI, a Snapchat, a Claude és az Anthropic elutasította a segítséget a kérdések több mint felében. Elrettentő példaként emelték ki, hogy a DeepSeek kínai MI-szoftver a fegyverekkel kapcsolatos tanácsait a következő mondattal zárta:
Vidám (és biztonságos) lövöldözést!
A Gemini a felhasználónak a zsinagógák elleni merényletekről folytatott csevegésben azt sugalmazta, hogy "a fémtörmelékek általában inkább halálosak".
A kutatók azt is felfedezték, hogy a Character.AI "aktívan" bátorít erőszakos támadások elkövetésére, egyebek mellett azt sugalmazta a felhasználónak, hogy használjon tűzfegyvert egy egészségbiztosító elnök-vezérigazgatója ellen, és bántalmazzon fizikailag egy politikust, akit nem kedvel.
A kutatás következtetései annál inkább megdöbbentők, mert "ezt a kockázatot simán el lehetne kerülni" - hangsúlyozta Imran Ahmed. "A Claude bebizonyította, hogy képes felismerni a kockázatokat és elrettenteni az erőszakcselekményeket. Ami hiányzik, az a szándék, hogy a fogyasztók biztonságát és a nemzetbiztonságot a gyors piacra dobás és a haszon elé helyezzék" - mondta.
Az AFP francia hírügynökség több MI-céget is megkérdezett a tanulmányról.
A Meta közölte, hogy megbízható védelem áll a rendelkezésükre az MI nem megfelelő válaszainak kiszűrésére, és intézkedéseket hoztak az érintett probléma orvoslására.
A Google szóvivője szerint a kísérleteket egy korábbi változattal végezték, amelyet a Gemini már nem használ. A belső vizsgálatuk bebizonyította, hogy a jelenlegi Gemini-modell megfelelően válaszolt a kérdések nagy részére, olyan információk közlése nélkül, amelyek nem találhatók meg egy könyvtárban vagy a klasszikus weben.
Kedden egy fiatal lány családja, aki megsebesült egy kanadai lövöldözésben, beperelte az Open AI-t, szemére vetve a vállalatnak, hogy nem értesítette a rendőrséget a támadó által a Chat GPT-nek írt aggasztó üzenetekről.
(MTI nyomán)